Table of Contents

Planning Actions, Not Predicting Tokens
The Best Reasoning Money (and Time and Compute) Can Buy
Co-authored by Barak Lenz, Yonatan Belinkov, Subbarao Kambhampati, Kevin Leyton-Brown, Yoav Shoham.
There is great interest today in AI that can reason better than traditional LLMs (if the seven-year practice of building LLMs can be called a tradition). “Reasoning” is of course a loaded term, but in the context of today’s AI it has come to mean exploring chains of tokens (including internal “thought” tokens, hence the term “Chain of Thought” or CoT), rather than myopically predicting only the very next token. Indeed, these CoT models are sometimes called Large Reasoning Models, or LRMs. In their incarnation thus far – for example, in the recent LRMs of OpenAI, Google, DeepSeek, X.AI, Anthropic, Alibaba, and others – a base LLM capable of producing solution guesses preceded by intermediate “thinking” tokens, is post-trained with a Reinforcement Learning (RL) phase to optimize for producing chains ending in correct answers. Then, at inference time, that model is allowed to pursue such chains up to a certain budget. The result has demonstrably improved performance on multiple tasks.
The point of this conceptual piece is to explain why this is a suboptimal way of exploring the space of possible answers to a given input, and describe a planning-based alternative. The purpose here is not to describe in detail the AI system built at AI21 – that’s a topic for a different paper, and we’ll only touch on it here – but to explain in more general terms how we see this space.
At a high level, here are the main messages:
- Think actions, not tokens. An action is any specific invocation of a given tool-–a specific prompt to an LLM, a specific web search, a specific database call, etc. Look for the best action sequences to take, not the best tokens to predict.
- The space of action sequences is huge. Explore it via explicit decision-theoretic planning, taking into account distributions over both answer quality and cost (in terms of time, compute and money). The plan is the outer loop; LLMs (and other tools) the inner.
- At training time, teach the system how to plan. At test time, create a specific plan and execute it, interleaving planning and execution.
- Involve the user throughout the process, especially at test time. The user is both the boss of the system and a resource for providing it with real-time corrective information.
Current “Reasoning” Models
Let’s begin by looking at some inherent limitations of the current LRM approach, and then discuss the alternative, as we see it. We should caveat this by saying that most LRM developers haven’t provided much detail about their models, so this is based on the one model – DeepSeek’s R1 – that was described in a fair amount of detail, and informed guesses about the rest.
We see two main categories of algorithmic limitations of LRMs. The first is inefficiency. At training time, for an input to carry a signal for the RL, the output must culminate in success sufficiently often. Even in the case of a not-COT LLM, since the operation of the LLM is stochastic, it is common to sample the output to each input K times, with the hope that at least one is successful. K is constant across all inputs, which is inefficient: for easy cases it’s an overkill, for hard cases it’s not enough, and for very hard cases no amount of sampling would be enough and so it’s a waste even to try. With CoT the problem is even worse, because CoT blows up the search space with “thinking tokens”. This means that for any given sampling budget—measured in tokens—LRMs explore an exponentially smaller subset of the tasks than LLMs. If LRMs exponentially increased the probability of finding a good answer within a reasonable budget, that would offset the downside of the larger search space. Yet that doesn’t seem to be the case empirically, and LRMs tend to run for a long time at great expense.
Another efficiency challenge is that the reward signal is given only at the end of the chain, and thus can’t be intelligently apportioned among the tokens in the chain. (This last point isn’t inherent to RL, and reflects the way it is used – again, as far as we can tell – in current LRMs. But it’s possible to apply Process Reward Modeling to provide explicit rewards to intermediate steps in the chain). In addition, you have space complexity limitations, since all the training is done by feeding an increasing set of chains into the context window. All these inefficiencies are amplified manyfold as you increase the set of tools, growing the search space correspondingly. Similarly, at test time there is inefficiency. An LRM is at the end of the day a language model, and at test time what you can do with it is feed it the input and do a forward pass. You don’t have much control over the length of the chains, can’t parallelize, can’t adapt it to the specific state of the compute resources, et cetera. Some of these limitations can be mitigated to some degree. It’s relatively easy to bias the model to produce longer or shorter chains; it’s possible to change the implementation so that chains can be followed in parallel and the results aggregated through some simple mechanism such as majority voting; et cetera. But we find these heuristic methods relatively weak compared to explicit control via deliberate planning, as we discuss below.
A separate, and perhaps deeper, algorithmic limitation of LRMs is their inability to generalize in a robust way. LRMs don’t really “reason” in the usual sense of the term. Reasoning is usually understood to be the rigorous application of trusted procedures, with predictable and correct outcomes, which apply to a wide class of tasks, e.g., the procedure for multiplication which applies to all valid inputs. LRMs don’t do that; instead, they probabilistically pursue useful chains of tokens. Sometimes those chains correspond to what one might call reasoning, but in general they do not, leading some of the authors of this document to describe these CoT models – only somewhat tongue in cheek – as “chain of thoughtlessness”, “large musing models” and “large mumbling models”. Whatever you call them, these models are best thought of as wonderful free associators rather than reasoners per se. There is ample evidence that these are not theoretical concerns but real shortcomings. For example, a recent paper shows that o1’s performance on a variety of combinatorial problems degrades extremely quickly with input size. At the end of the day, sample complexity comes back to haunt you.
Before discussing ways around these issues, let us briefly mention a few other issues that are critical in the enterprise and that pose further problems for the deployment of existing LRM architectures.
- Transparency, understandability, and controllability. Learned LRMs are opaque. The user has limited visibility into the chains – even in the implementations that provide traces of the chains, those tend to not reliably capture the search performed by the LRM. And the user certainly can’t control the chains.
- Predictability and guarantees. Like LLMs from whence they come, LRMs are probabilistic, prompt-and-pray machines. Even a simple flow consisting of a single prompt to an LLM produces different responses on different tries, and the variance grows with the complexity of the flow. In the enterprise, offering nondeterministic responses is a nonstarter—being brilliant 95% of the time but nonsensical the other 5% simply won’t cut it.
- Customizability. Everything in the process – from the pretraining, to the post training and test time computation – is sensitive to the domain. In particular, different enterprises have different tools, different use cases, different policies, and different compute options. The AI needs to somehow align itself with the specific environment, but LRMs don’t lend themselves to easy customization; at best you can influence them via the prompt, but that gets you only that far, and offers no robustness guarantees. In particular, it doesn’t allow you to link in tools that were not available during pretraining. And retraining an LRM for each new environment isn’t practical.
The Alternative: Planning in the Space of Actions
There have been various suggestions about how to compensate for the limitations of LRMs, which generally fall into an emerging area dubbed “AI systems”. While details differ, common to this approach is committing to the idea that large models—whether LLMs or LRMs—aren’t the end all and be all, but instead part of a larger system that contains multiple elements and orchestrates their use. In LRMs (and LLMs as a special case) the end result is a model, and at test time, a standard forward pass is performed through the model (albeit with “thinking tokens” in, e.g., R models). In contrast, “AI systems” have an external controller at both training and test time that invokes various tools; the controller is the outer loop, and the LLMs and other tools are on the inside. The LLM becomes a tool in service of the orchestrator, albeit an important one.
Apropos the last sentence, let us at the outset dispel a possible misconception. This paper might be wrongly interpreted as us saying that LLMs and LRMs are not important. They are. LLMs are an amazing combination of the world’s biggest knowledge repository and Kahnemanesque System 1 thinking. LRMs are wonderful ideators. Both LLMs and LRMs suffer from high variance, but are critical elements in a reliable, controllable and predictable System 2 AI, as we discuss below.
Perhaps the simplest way of building an AI system is to add verifiers to existing models. It then becomes possible to use a simple controller to verify the output of the L(L/R)M, and if the check fails attempt to do better somehow or tell the user that the system failed.
We believe that verifiers are indeed critical, at both training and test time, but that alone they aren’t enough. They tell you whether a proposed output is good, but don’t help you find the potentially good outputs. To find the good outputs in the haystack of possible outputs you need to perform an intelligent search, and the first thing is to be clear about the space you’re searching. The space that enables systematic search for solutions is not the space of token sequences, but the space of action sequences. The set of actions includes the Cartesian product of tools and possible inputs to the tools. For example, if you take a given LLM as a tool, the set of actions associated with the tool consists of all candidate prompts, combined with other high-level parameters such as the temperature, random seed, or the number of generations. So the set of actions is vast, and the set of action sequences vaster. Search in the space of action sequences is planning. We see this as a key missing ingredient in the recent AI approaches.
There is a rich literature in AI on planning, starting with deterministic heuristic search methods of the 1980s, and continuing to the stochastic methods more common today. A common method of planning in stochastic domains is Monte Carlo Tree Search (MCTS). This is precisely the method used in a recent paper by Schultz et al, which showed that an outer MCTS planning layer materially improves on the performance of the raw model in game playing.
At AI21 we believe that learning both how to plan and how to execute plans is key to achieving robust AI, though by itself MCTS is insufficient. Without going into specific details (again, this is a topic for a different paper), we believe the following elements are key to achieving robust, planning-based AI systems:
- A clear language in which to describe plans. At AI21 we’ve developed such a language, which is an expressive yet well behaved subset of Python (we’ll share the details soon).
- Clear objectives. To paraphrase the Cheshire cat, if you don’t know where you’re going, you’ll never get there. You should capture in as structured a manner as possible the task, the tools available, the hard constraints on the output, and any other relevant elements such as the available budget (time, money) and relevant policies. Now you’re ready to plan.
- Modeling costs and success probabilities. For each step in the plan, you should explicitly model the distribution over the costs involved (in terms of time, compute and $), as well as the distribution over the quality of the output.
- Decision-theoretic planning. Modeling cost and success probabilities enables decision-theoretic planning, both at training time (to precompute plans for common tasks) and at test time (to instantiate and adapt the pretrained plans, and to create novel ones). At test time an initial plan is constructed based on the priors, and only at the appropriate granularity. Certain actions can’t be planned before you see the specific input, and certain actions can’t be usefully planned before you see the output of other actions. Planning and execution must therefore be interleaved.
- No generation without verification. Each step in the plan has a verifier associated with it, whether a hard one encoded in a deterministic procedure, or a soft heuristic one (for example, performed by a Judge Language Model).
- “Anytime” execution. At test time provide a good baseline output quickly, and keep improving on it as long as there’s reason to believe improvements are possible, and as the budget allows.
- Parallelism. Parallelize like there’s no tomorrow. Well, within budget.
- Human in the loop. At test time, involve the user throughout the process. The user is the boss, but also in a sense a tool in service of the system. Validate the task as you extracted it. Share the initial plan at the appropriate level. Share the execution progress at the right times. Provide the user guarantees of the quality and costs of your plan to the extent you can, and say when you can’t.
- Humility. Reject a task when needed; not all tasks are achievable, and users will lose trust in the system if it claims to have a good plan when it doesn’t.
Our goal was to describe the ideas rather than the specific offering of AI21, but to get a concrete sense for the benefits, here are some results from Maestro, our planning and orchestration system.
This first graph shows the benefit of wrapping Maestro around LLMs with two types of verifiers: a heuristic LLM-as-a-Judge, and deterministic code verifiers.
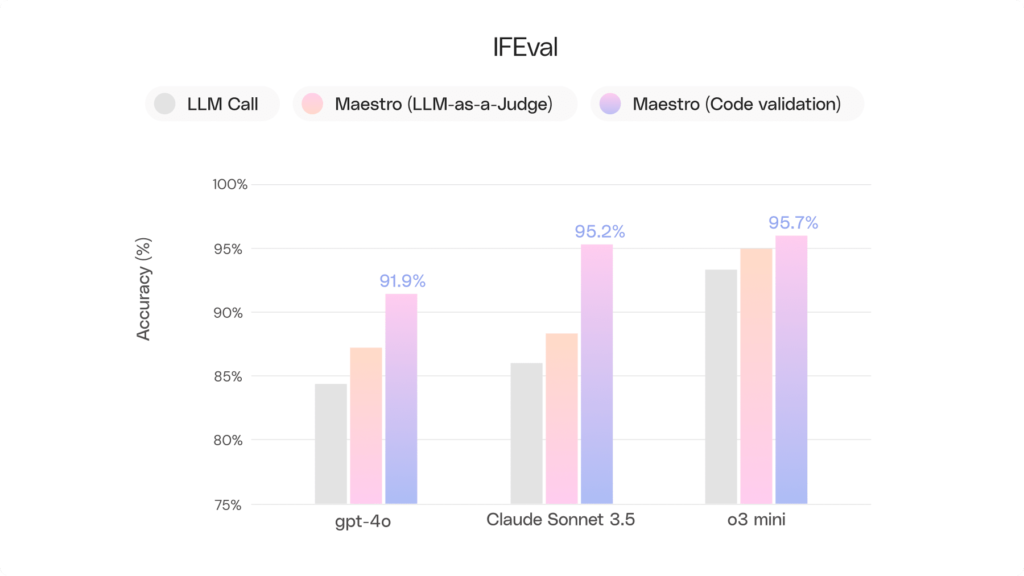
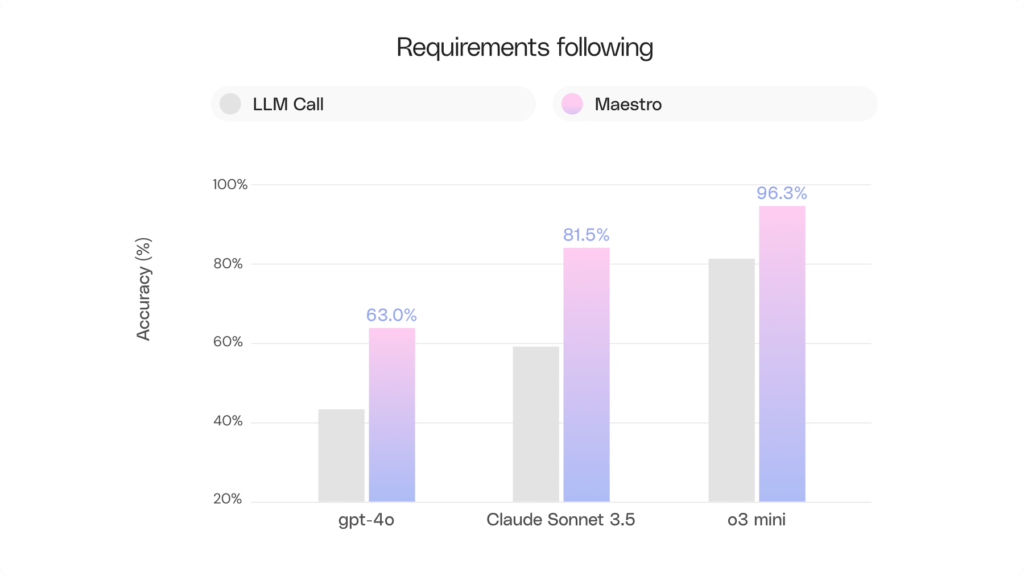
The second chart shows how wrapping an LLM call in Maestro boosts the accuracy of following multiple user requirements:
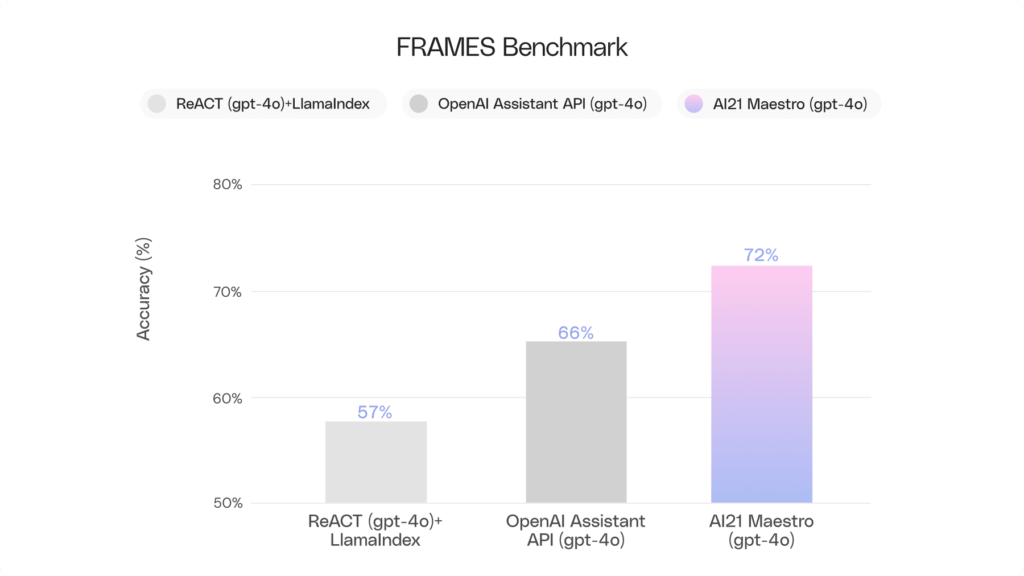
Finally, the third chart shows that Maestro is a better way of boosting an LLM performance on complex retrieval and reasoning tasks than are either OpenAI’s Assistants API or ReACT:
We invite you to sign up to kick the tires of Maestro, though, as it’s currently in closed preview, we beg your patience.


