Table of Contents

Maestro: Making Complex Tasks Simple

Welcome, Maestro! The one system to plan and execute them all.
In this post, we’ll introduce Maestro’s intelligent planning capabilities and how it determines the optimal course of action to solve complex tasks, with a specific focus on generating with requirements as one powerful use case. It’s also connected to built-in file search (RAG system) and web search. We’ll explain how to use Maestro to solve complex problems or improve existing pipelines, and demonstrate how it enhances even the best LLMs available today.
What does Maestro do?
It’s exactly what it sounds like: instead of writing an elaborate prompt containing multiple instructions, users can separate their input into an instruction and a set of requirements. The requirements can be in terms of content, style, format, genre, point of view, and various guardrails. Maestro validates the output against requirements throughout the generation process, ensuring they are met. It then produces a result, provides a score for each requirement, and gives detailed feedback on any that aren’t satisfied.
This might seem like adding extra work instead of just providing a single instruction. Why not just extract the requirements from the full instruction automatically?
Yes, it adds some work, but as the saying goes – it’s a feature, not a bug. Simply put, specifying requirements explicitly lets Maestro validate the output during generation and provide feedback, giving users more control and visibility.
How does Maestro plan and execute tasks?
At its core, Maestro is a dynamic planning system that determines the optimal sequence of actions to solve a given task during inference time. The system excels at self-validation and correction, continuously evaluating outputs against your specified requirements.
Unlike traditional approaches that rely on a single generation attempt, Maestro uses inference-time compute scaling to validate results and make improvements iteratively. Rather than following a fixed approach, Maestro intelligently plans the most efficient path to achieve your goals.
Usually, more compute translates to higher quality. Maestro leverages this principle by implementing a sophisticated planning mechanism. By providing a quality threshold and a budget, Maestro will plan and perform the task while adhering to both the budget limitation and the quality threshold. At any given moment, there’s a candidate solution, and Maestro continues to improve upon it until all requirements are met or the budget is exhausted.
Essentially, each call to Maestro builds a tree of calls to LLMs and other tools. Based on the task requirements and available budget, Maestro strategically plans which techniques to employ. Some examples of techniques Maestro might include in its execution plan are:
- Best-of-N: Every LLM call is generated multiple times, either with different models or the same model with high temperature. Candidates with low success probability are disregarded. This method relates to the breadth of the tree.
- Generate and fix: Every promising candidate (one that received a good score or is deemed easily fixable) goes through a revision loop, where the generation and feedback feed into another generation (which may also use the Best-of-N method). This method relates to the depth of the tree.
These are just two examples of the many techniques Maestro can incorporate into its dynamic planning process. The system continuously evaluates which actions will yield the best results given the remaining budget and adjusts its approach accordingly.
It’s not just algorithmic techniques that make Maestro unique; a lot of engineering considerations went into the building process. Maestro’s smart execution mechanism, which understands dependencies within the executed code, optimizes the performance of the entire system by balancing parallel and sequential operations.
Combining all the above creates a system that can solve problems quickly while continuously improving results until reaching the budget limitation.
What does this enable?
Using Maestro will allow any developer to:
- Work faster – developers who build an entire system themselves for a production environment know that it’s much more complicated than any Jupyter notebook tutorial or a 15 minute youtube guide. It requires manually planning a complex workflow, which encompasses evaluating and deciding which model performs best, defining validation logic, recovery from errors and much more. Instead, you can simply call Maestro and get quality guarantees according to your budget.
- Work smarter – if you notice a trend of outputs that aren’t good enough, it likely means you need to add a requirement. For instance, while using Maestro on code generation at scale, we found that certain outputs were consistently failing. Upon examining them, we noticed that there was an issue with strings that contained an apostrophe (which, if not preceded by a backslash, will cause errors). By adding this specific requirement to Maestro, we fixed the problem immediately.
Does it work?
We evaluated Maestro on two different types of problems: complex RAG systems and requirements following.
Complex RAG systems
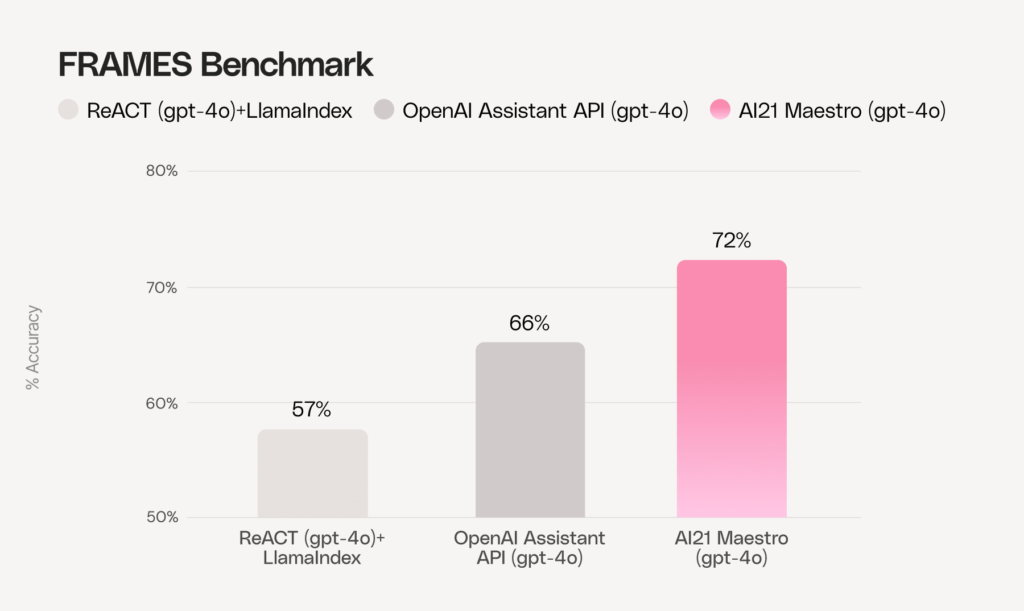
To evaluate how Maestro enhances common systems in solving complex problems within RAG pipelines, we tested its performance on the FRAMES benchmark. This benchmark presents particularly challenging multi-hop questions that require systems to retrieve and integrate information across multiple documents while performing complex reasoning tasks. You can see that Maestro, which uses dynamic planning, outperforms existing agentic systems which rely on LLMs to make decisions during run time.
Requirements following
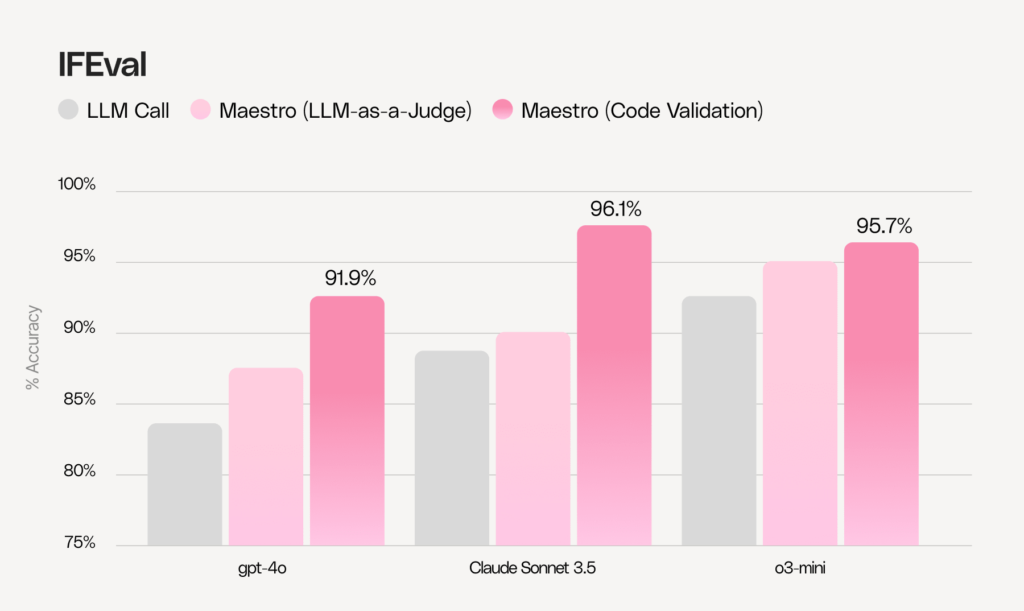
The evaluation of Maestro was done on several datasets with various methods.We tested Maestro on IFEval, a widely recognized dataset that contains verifiable instructions which can be verified by heuristics.
Our evaluation employed two distinct approaches:
- LLM-as-a-Judge: We converted the validation functions into semantic requirements (for instance, transforming “no_comma” into “In your entire response, refrain from the use of any commas.”). These became our requirements for Maestro to satisfy.
- Code validation: We implemented these validations programmatically, enabling more precise assessment during Maestro’s improvement iterations. This leverages one of Maestro’s key features of allowing developers to use their own validators as part of the system.
As shown in the graph below, Maestro achieves substantial improvements over standard LLM calls, further demonstrating its effectiveness across different types of requirements.
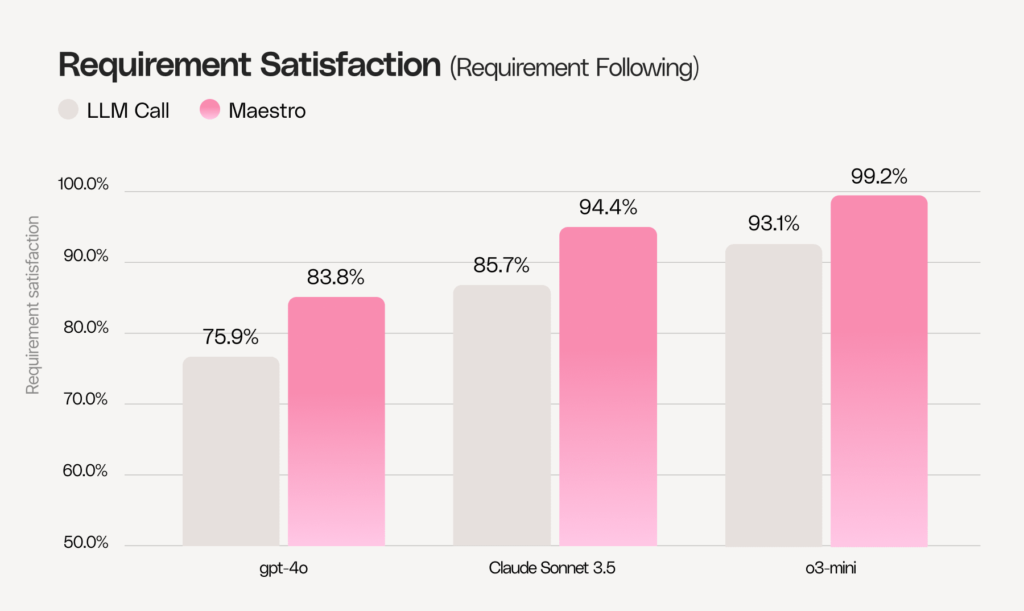
We also developed a dataset called “Requirements Following.” This dataset contains heavily constrained instructions, emphasizing grounding tasks such as question answering and summarization. The requirements primarily focus on format, tone, and grounding, among various other specialized requirements.
Here’s an example from the dataset:
Instruction:
Pretend you are a business coach who helps professionals become leaders. Give an overview.
Requirements:
- Answer In just 50 words
- Produce an overview of only what the the input text says about listening
- Write leader(s) or manager(s) in italics every time it appears
- Don’t mention any specific people in your output
As you can see, the instruction isn’t written in a specific format; the requirements are also quite loosely phrased and can include different aspects, from length to style to content specifications.
We measured quality on that dataset using two metrics. The first is “requirement satisfaction,” which measures how many requirements are satisfied. The graph below shows the percentage of fulfilled requirements across all examples in the dataset (validation uses an LLM as a judge). Even for advanced models like o3, where the original score is already high, Maestro still delivers substantial improvement.
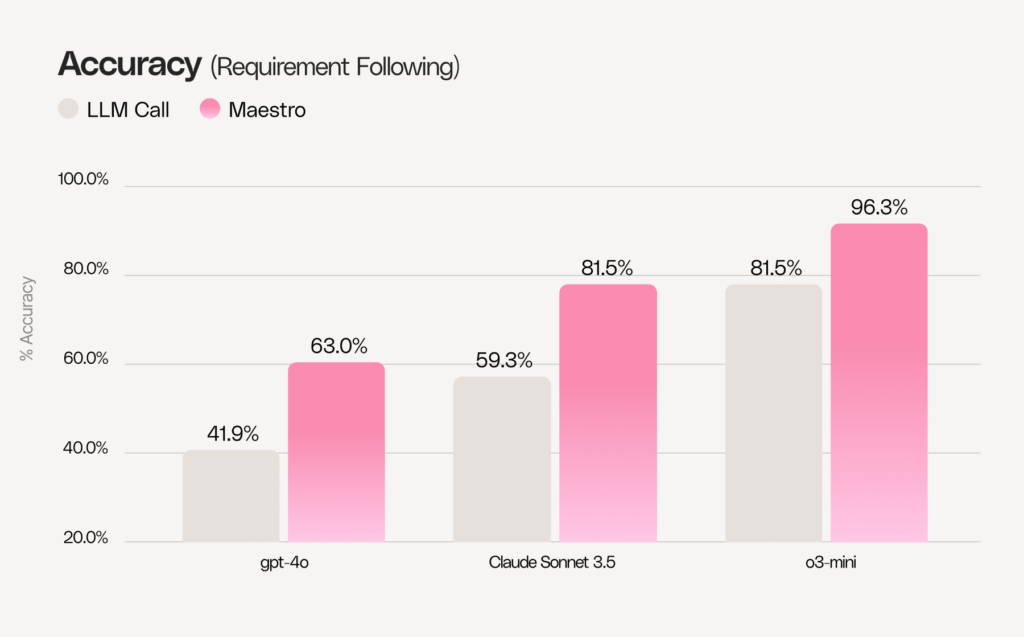
The second metric is “accuracy,” which is more stringent: we measure all samples that received a perfect score (i.e., all requirements fulfilled). You can see there’s a significant gap between baseline performance and Maestro-enhanced results.
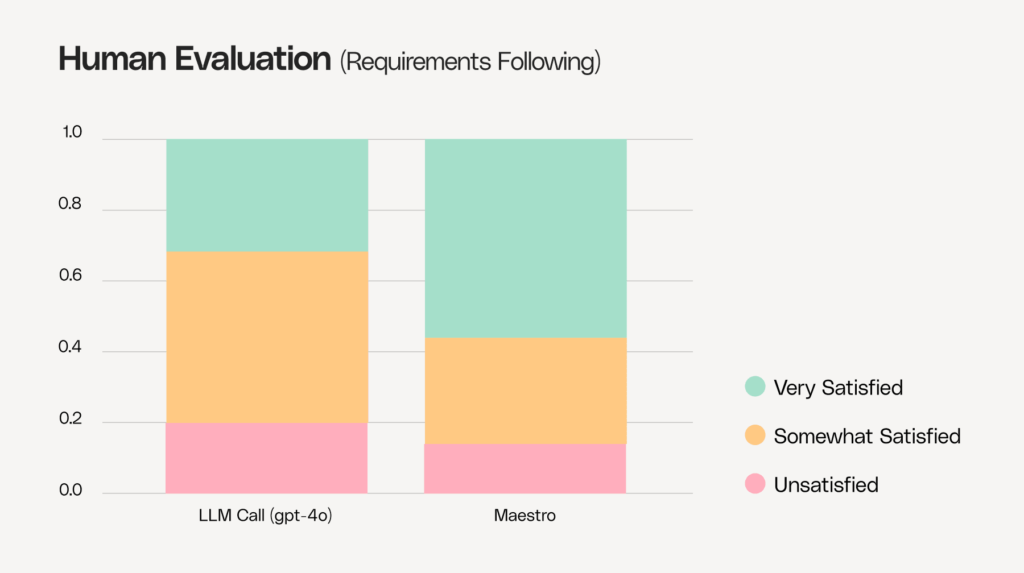
We also performed human evaluation. Human professionals conducted blind evaluations in a methodological process measuring the level of satisfaction: very satisfied, somewhat satisfied or unsatisfied. Below, you can see how Maestro substantially increased the very satisfied rate while significantly reducing the unsatisfied rate compared to a single call to gpt-4o.
Conclusion
Maestro provides developers with unprecedented control over LLM outputs through intelligent task planning and explicit requirement definition. By dynamically planning the optimal sequence of actions and separating instructions from requirements, we’ve created a system that consistently outperforms even the most advanced models on complex tasks.
Spend less time on prompt engineering and workflow design, and more time building what matters. The data speaks for itself – Maestro delivers higher-quality outputs that better satisfy your specific requirements while optimizing your compute budget through intelligent planning.
Want to get your hands on Maestro? Join the waiting list for early access.


