Table of Contents

AI21 Receives a Top Score on Stanford University’s Transparency Index

We are proud to announce that we AI21 Labs was recently awarded the highest transparency score among commercial general purpose LLMs—and the second highest score overall—on Stanford University’s prestigious Foundation Model Transparency Index (FMTI).
AI21 builds cutting-edge language models for our enterprise clients, and we know how critical transparency and accountability are to our clients. Companies have been asking all LLM providers for greater transparency and we listened.
By sharing more information about our models and scoring high on indicators around customer feedback, we demonstrated the greatest improvement in our score among the 10 companies who had been surveyed previously, jumping from 25 in October 2023 to 75 just six months later.
This score places us well above the mean score of 58, as well as above major companies in the LLM space, including OpenAI (49), Anthropic (51), and Meta (60).
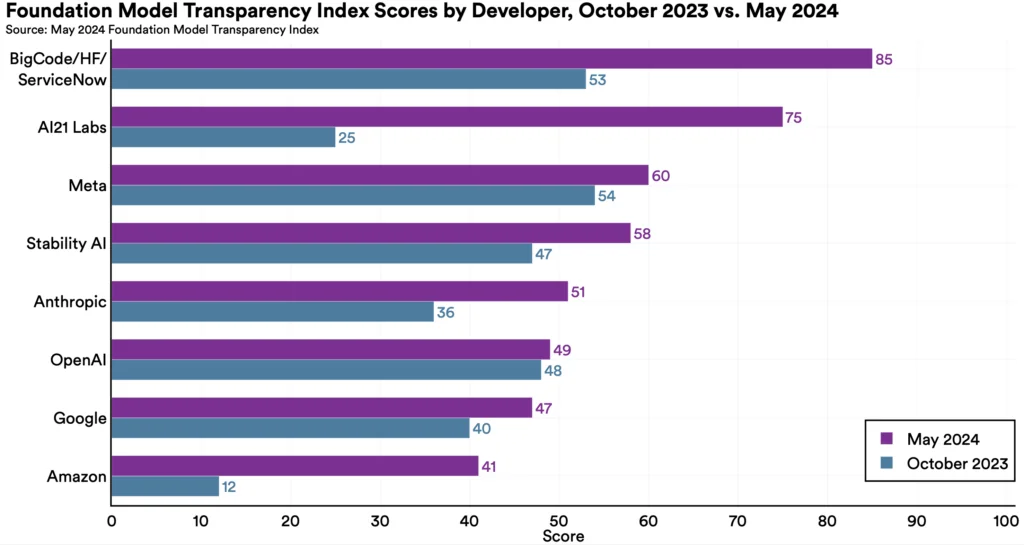
In a market saturated with a variety of LLM vendor options, this high score distinguishes AI21 from its competitors and underscores the reliability of our generative AI models.
The Foundation Model Transparency Index
First published in October 2023, the FMTI is an initiative of Stanford University’s Center for Research on Foundation Models (CRFM) and the Institute on Human-Centered Artificial Intelligence (HAI), and in partnership with the MIT Media Lab and Princeton University’s Center for Information Technology Policy.
The Index was developed to measure and grade leading LLM developers on their company and model transparency, with the understanding that developing cutting-edge technology carries a significant responsibility and model providers should be held accountable.
Many governments have similarly recognized the power of this technology, cementing AI systems transparency as a pillar of new Executive Orders and, now—in the European Union—law.
Model developers are scored across a rubric of 13 transparency metrics, including data, compute, methods, usage policies, and feedback, with each metric comprising several indicators. All together, companies are evaluated on the basis of 100 indicators, with each one representing a point on a 100-point scale.
AI21 Labs particularly excelled in disclosing data sourcing, creation, and augmentation practices; compute and hardware specifications; extensive information about the development of the Jurassic-2 model and its technical features; clear and enforceable usage policies; and outlined mechanisms for client feedback. Recognizing the importance of transparency in the AI field more broadly, and for our clients specifically, we made a concerted effort to document and share more information in this current round. Accounting for more than half of our awarded points, this increase in our score reflects the practices around transparency we have incorporated into our operations.
For a full detailing of the FMTI’s methodology and analysis, you can read the research team’s paper here.
Transparency for the enterprise
Companies who wish to leverage the power of GenAI in their workflows know that it’s not enough to simply build a prototype. Integrating a safe, reliable, and scalable AI system requires strategic thought, top-of-the-line models, robust infrastructure, and secure data storage and deployment options.
Just as companies must constantly take a whole host of regulatory and legal considerations into account in their daily operations, GenAI is no different. At AI21, we build LLMs specifically to solve common enterprise challenges, keeping in mind the critical need across highly-regulated industries, such as finance and health care, for accurate and reliable output.
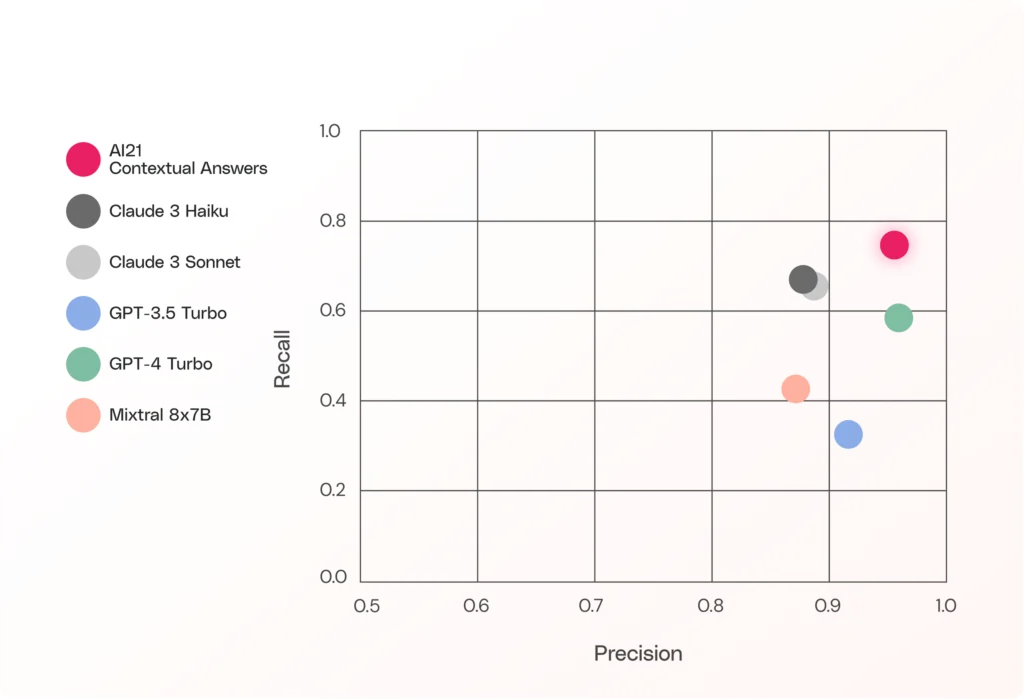
For example, Contextual Answers, our Task-Specific Model that enables question answering across your organizational knowledge base, grounds all output in the provided context to avoid hallucinations. If the answer isn’t there, the model will let you know, rather than making something up.
And our latest and most advanced Foundation Model, Jamba-Instruct, has the largest context window in its size class, at 256K. With such a massive context window, it is able to ingest more input text at once, producing more comprehensive, coherent, and accurate output as a result.
While the current FMTI evaluated our Jurassic-2 Foundation Model, we built the newly-released Jamba-Instruct with the same core company values that earned us a top score on this recent round of the index, and we eagerly anticipate submitting our new FM in the next round of scoring.
Interested in learning more about our GenAI solutions for the enterprise? Book a call with one of our experts.


