Table of Contents

Build a dashboard based on freeform sentiment analysis of hotel reviews

Imagine that you have a platform for hotel reservations, similar to Hotels.com. On your platform, hotel visitors can leave written reviews and an overall star rating for the hotel. These reviews allow hotel owners to gain a general understanding of guest satisfaction through their overall score, but that’s just one part of the story. The quality of the hotel experience is a combination of many factors, including the room quality, the facilities, and the staff. Ideally, the owner would like to get a clear picture of their hotel’s strengths and weaknesses so they can improve on the aspects that are lacking and highlight the aspects that visitors find positive.
To extract these insights, some hotel owners sit down from time to time and read all of the reviews that were written about their hotel. This is a tedious task – one you, as a developer, would probably want to spare your users from. What if you could create a dashboard that highlights the areas guests mention positively or negatively in their reviews? As a result, your user – in this case, the hotel owner – can get a real-time snapshot of their strengths and weaknesses with just a glance at this dashboard.
Not so long ago, you would have needed to work pretty hard to create a solution like that (for example, using several classical methods). But with large language models (LLMs), it’s really easy. You can perform this analysis with high accuracy, even with no prior knowledge of natural language processing (NLP). If that sounds appealing to you, then read on. By the end of this post, you will be able to implement this feature in your platform or product.

This post will walk you through the process of building an NLP-powered dashboard for a hotel, including:
- Using an external API to gather real-world data.
- Performing freeform combined topic extraction and sentiment analysis using Jurassic-1, part of the AI21 Studio suite of large language models.
- Generating the output in a convenient format (JSON) so it’s easier to process.
If you are new to large language models, we recommend first reading this post.
Step 1: Collect reviews using an external API
You can find the Hotels.com API on RapidAPI. There are several endpoints to this API. We need the reviews endpoint, that returns the reviews for a given hotel, page-by-page. There are approximately 50 reviews per page. In order to retrieve all of the available reviews we will call the API while iterating through the pages. The following functions do just that:
def get_hotel_reviews_page(hotel_id, page_number):
params = {
"locale": "en_US",
"hotel_id": hotel_id,
"page_number": str(page_number)
}
headers = {
"X-RapidAPI-Key": RAPID_API_KEY,
"X-RapidAPI-Host": "hotels-com-provider.p.rapidapi.com"
}
response = requests.get(url=GET_REVIEWS_URL, headers=headers, params=params)
reviews = [
review['summary']
for page_reviews in response.json()['groupReview']
for review in page_reviews['reviews']
]
return reviews
def get_hotel_reviews(hotel_id, num_pages):
all_reviews = sum(
[get_hotel_reviews_page(hotel_id, page_number) for page_number in range(1, num_pages + 1)],
start=[]
)
return all_reviewsNote that running this function requires an API key for the reviews endpoint, which you can obtain from RapidAPI. This is not your AI21 Studio API key. There are some edge cases that this function doesn’t cover, such as requesting a page number that doesn’t exist, but we’ll set them aside for the purposes of this blog post.
Throughout this process, we will use the Empire Hotel in New York as a running example. You can use an API endpoint to get the hotel ID, or you can find it in the hotel’s URL on Hotels.com:
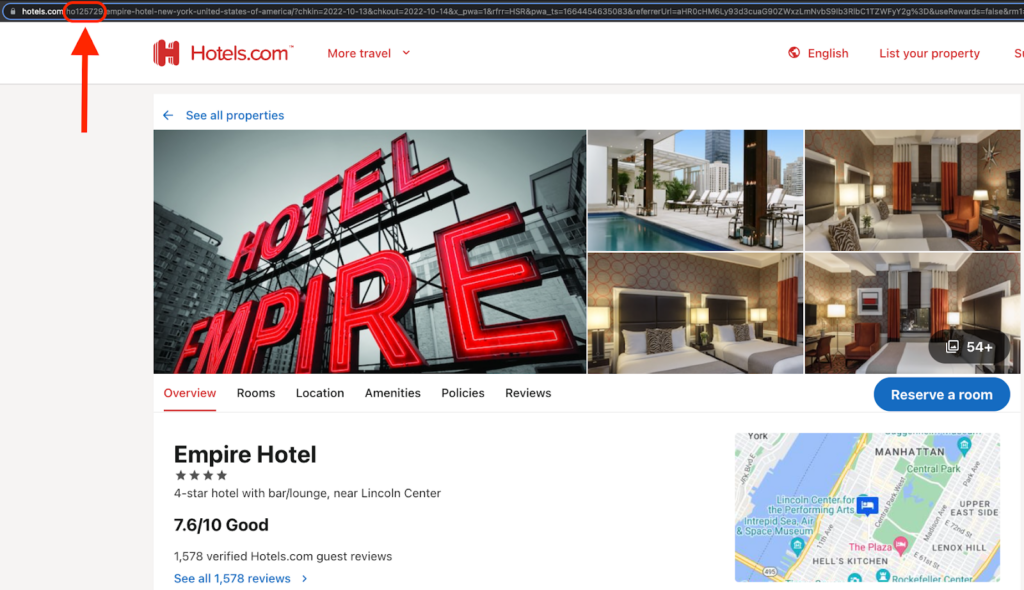
Step 2: Prepare the reviews data for the language model
Large language models are very powerful and can ingest text of all shapes and sizes, but as the old saying goes, “garbage in, garbage out”. If you feed the model a bad prompt, the results will be far from optimal.
In this case, you should keep the following points in mind:
- Reviews that are too short could be problematic since they often do not contain enough information to extract any meaningful insights.
- Currently, our models are limited to the English language only.
In order to remove reviews that are too short or not in English, you can apply some simple filters to all of the reviews:
from langdetect import detect
def filter_reviews(reviews):
en_reviews = [review for review in reviews if len(review)>=20 and detect(review)=="en"]
return en_reviewsNote: Here, we have removed reviews that have no real content by applying a very basic filter. Although this is not mandatory, we recommend that you pre-process your reviews by, for example, removing weird characters and extra spaces, etc.
Step 3: Extract the categories and sentiments using AI21 Studio
This step is where you truly harness the power of AI21 Studio’s large language models!
You want the model to extract the topics and sentiments of each free text review into a structured JSON format. You can do this by leveraging a main strength of language models: when provided with text in plain English, the language model can identify patterns and generate text that follows the same pattern. By feeding the model a prompt with a few examples (this is called a few-shot prompt), it can identify the pattern and generate a reasonably good completion.
Obtaining these examples, however, requires you to manually go through several reviews, which we have done below. The resulting few-shot prompt is as follows (the reviews are as written by the platform’s users, with no grammar or spelling corrections):
Review:
Great experience for two teenagers. We would book again. Location good.
Extracted sentiment:
{“Location”: “Positive”}
##
Review:
Extremely old cabinets, phone was half broken and full of dust. Bathroom door was broken, bathroom floor was dirty and yellow. Bathroom tiles were falling off. Asked to change my room and the next room was in the same conditions.
The most out of date and least maintained hotel i ever been on.
Extracted sentiment:
{“Cleaning”: “Negative”, “Hotel Facilities”: “Negative”, “Room Quality”: “Negative”}
##
Review:
Roof top’s view is gorgeous and the lounge area is comfortable. The staff is very courteous and the location is great. The hotel is outdated and the shower need to be clean better. The air condition runs all the time and cannot be control by the temperature control setting.
Extracted sentiment:
{“Cleaning”: “Negative”, “AC”: “Negative”, “Room Quality”: “Negative”, “Service”: “Positive”, “View”: “Positive”, “Hotel Facilities”: “Positive”}
##
Creating a good prompt is more than simply deciding on the pattern. The goal is to construct a prompt that triggers the model to generate the optimal completion (this is called prompt engineering). To achieve this, you should keep the following in mind:
- Variety: the examples in the prompt will determine the model’s responses for unseen data, so they must be diverse enough to reflect the real-world distribution. This applies to both the structure of the reviews (such as length) and the content (the topics discussed in every review, the sentiments, etc.). Be sure to include reviews that are mixed in sentiment (like the third example provided above), as these are usually harder to analyze.
- Amount: how “few” examples should our few-shot prompt include? When it comes to this relatively complex task, it is recommended that you provide at least eight different examples in the prompt (depending on the number of topics and the variety within them). The most effective way to determine this is through testing it out in the playground. Try it yourself!
Additionally, in this use-case, we recommend setting the temperature to 0, as high accuracy is required more than creativity. Increasing the temperature will result in more creative results, while lowering the temperature will increase their accuracy. Curious about temperature? See Step 4 in this post for more detail on this.
Happy with the prompt and want to start analyzing reviews? You can copy the few-shot prompt from the playground:
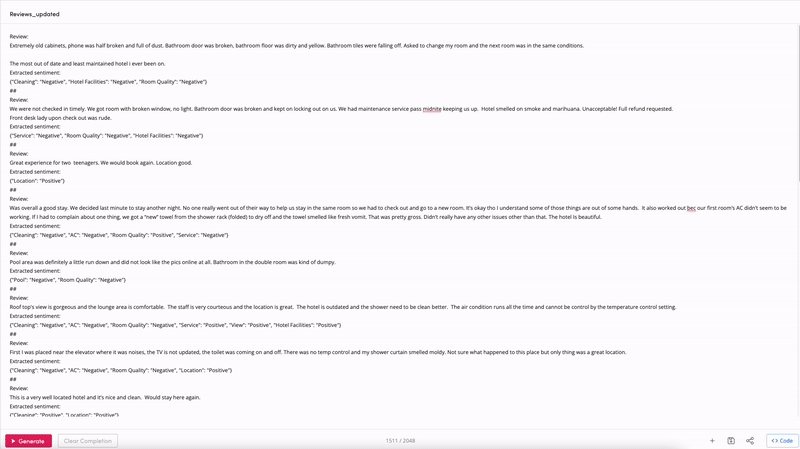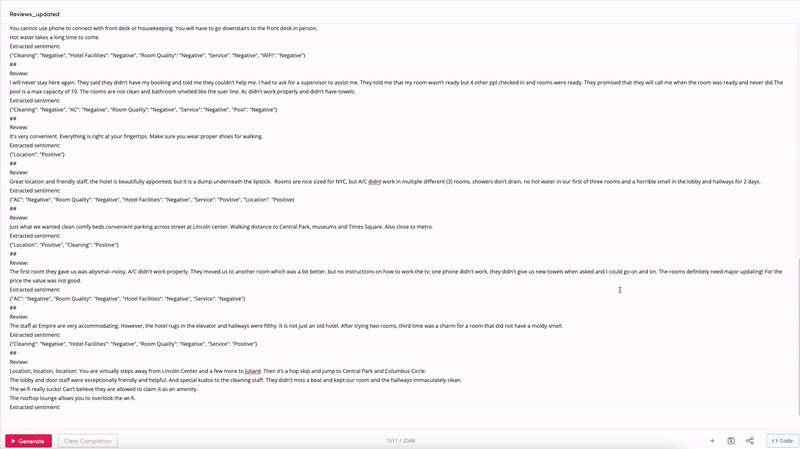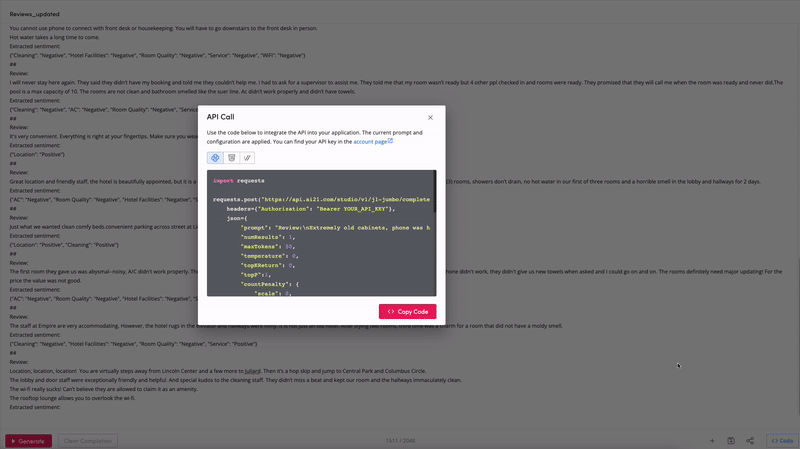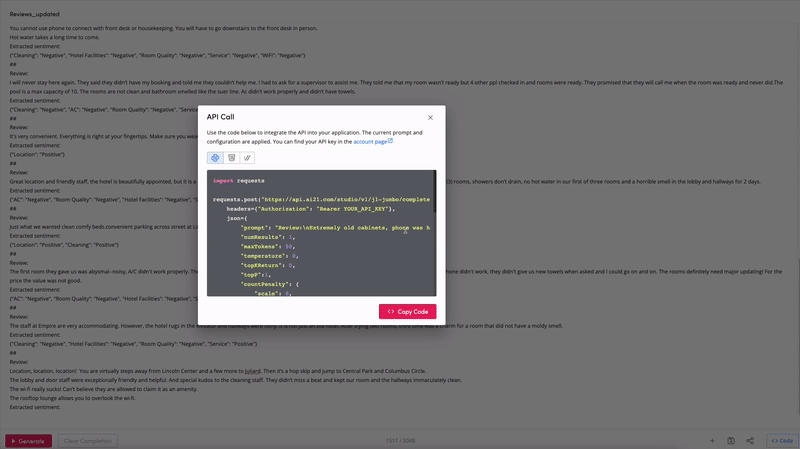
And use the following function to create the prompt for every review:
def create_review_prompt(review):
few_shot_examples = FEW_SHOT_EXAMPLES
prompt = few_shot_examples + review + "nExtracted sentiment:n"
return promptFor every review, create the prompt and then call Jurassic-1 to perform the analysis (you can take the call from the playground, as illustrated above, or use the function from here).
Step 4: Create the dashboard
Once you have the list of topics and sentiments, you can create your dashboard.
First, gather all of the topics together, assigning a count of “Positive” or “Negative” to each topic. Since you already have the completion in JSON format, you can process it using standard packages. However, as the format may not be perfect, and you don’t want any failures in your automated process, you can add a simple try-catch block. This means if a completion from the model isn’t in perfect JSON format, you drop it. You can use the following function:
def get_topK_categories_and_score(sentiments, k=7):
parsed_sentiments = []
for sentiment in sentiments:
try:
parsed_sentiments.append(ast.literal_eval(sentiment))
except SyntaxError:
pass
df = pd.DataFrame(parsed_sentiments)
# extract the K categories with the most reviews
keys = df.count().sort_values(ascending=False)[:k].index.tolist()
category_names = ['Negative', 'Positive']
scores = {}
for key in keys:
scores[key] = [(df[key] == category_names[0]).sum(), (df[key] == category_names[1]).sum()]
return scores, category_namesAt this stage, all that’s left to do is create the figure. With minor changes to this matplotlib example, you’ll have your dashboard:
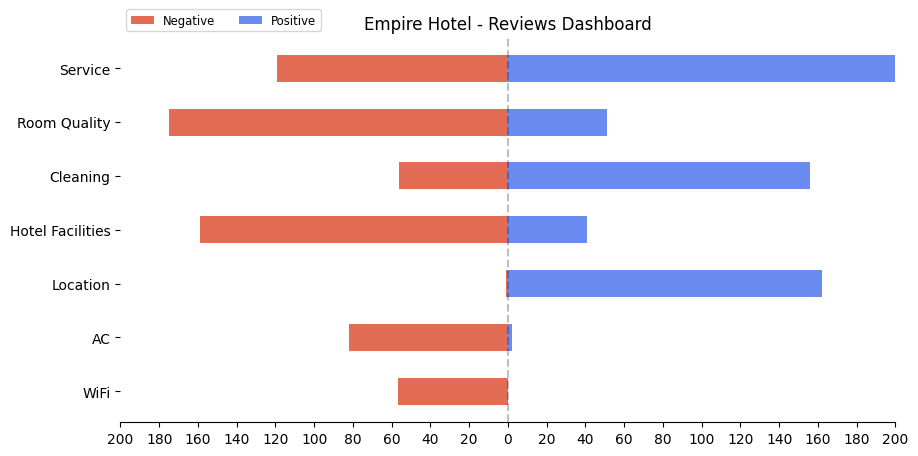
You can see that the hotel is deemed excellent in Location and rather good in Service and Cleaning. However, it should invest more in the WiFi and AC, and perhaps do some renovations or upgrades to the rooms and facilities.
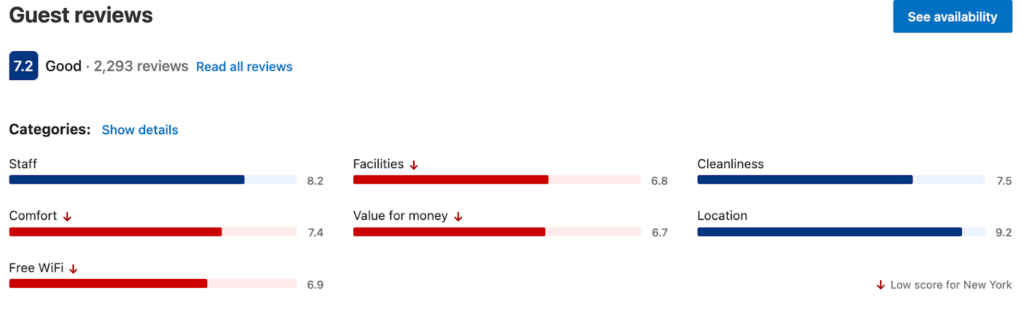
As a last step and some sanity check, you’ll probably want to validate your results, but without manually reading every review. One way to do that is to compare them with those of other hotel platforms, such as Booking.com. If you go to the Booking.com page for this hotel, where visitors are asked to rate hotels across numerous categories, you will find the overall picture is very similar to your own analysis:
Summary
By following the steps laid out in this post, you have built a very useful feature that can be implemented on hotel and accommodation platforms. Thanks to large language models, analyzing pieces of text, such as reviews, has never been easier. A few simple tweaks, such as writing the examples in JSON format, can save a lot of time in post-processing, making the entire process faster and easier. You can find the full notebook in our dev-hub.
Are you interested in building your own feature? With a custom model, you’ll always get the highest quality results. You can find out more about that here.


