Table of Contents

Build Conversational AI Applications Grounded in Your Enterprise Data
For enterprises that are (rightly) concerned with the factuality and quality of the output of their GenAI applications, retrieval-augmented generation (RAG) is arguably one of the most valuable strategies an enterprise can use to ground queries in their private data.
Yet to make a RAG system truly scalable, it needs to go beyond single-turn question answering. Infusing RAG with multi-turn chat capabilities and dynamic planning strategies allows it to become a reliable thought partner for getting work done and delivering reliable customer support experiences, from internal employee research tools to customer chatbots.
In this post, we’ll discuss how conversational RAG solutions are built to deliver high quality output for internal and external enterprise applications, before walking through how to build a financial analyst assistant.
A collaborative AI system
Knowing that one-shot questions and answers to a RAG Engine or an LLM are not enough—nowhere near sufficiently passing the bar of enterprise quality—we instead bring these components together in one compound AI system in order to retrieve the highest quality answer for your business.
Using this more holistic approach, as depicted in the diagram below, Conversational RAG is able to use planning to assess each incoming query, determining whether it can answer from the LLM’s intrinsic knowledge or whether it should turn to the RAG Engine.
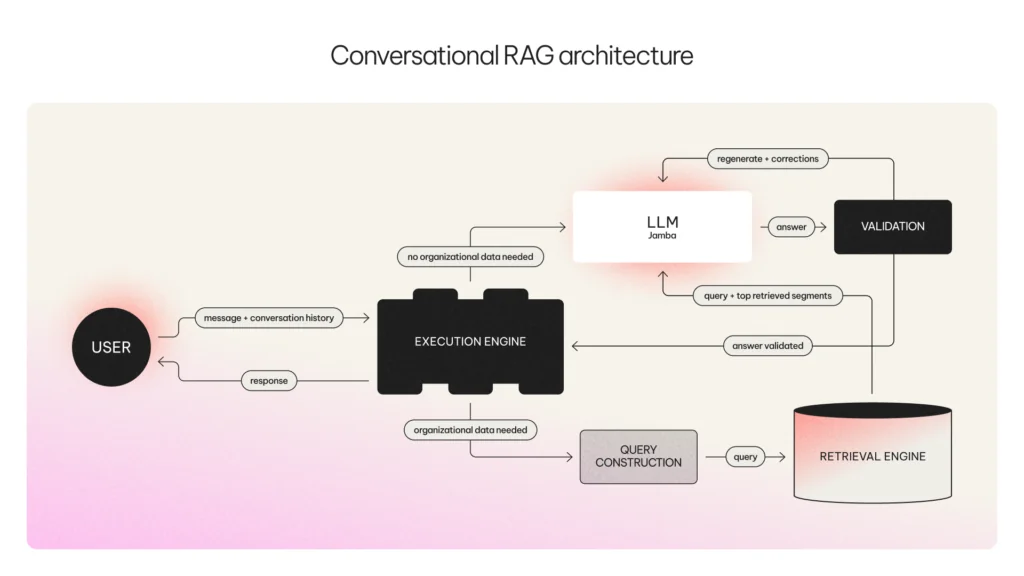
And as a fully-managed service, all you need to do is upload your documents (in PDF, TXT, DOCX, or markdown formats, with data connectors coming soon) and AI21 takes care of automatically indexing them in the most optimal way within the built-in RAG Engine.
Building a financial analyst assistant
In this tutorial we will build a financial analyst assistant. Follow along with the steps below or with this video:
First, we want to upload any relevant files to the RAG Engine. In our case, we will use 10-K forms of Amazon from the last 5 years. You have the option to do it easily through our UI, or using the following code:
# Downloading the forms
os.mkdir("data")
!wget 'https://d18rn0p25nwr6d.cloudfront.net/CIK-0001018724/c7c14359-36fa-40c3-b3ca-5bf7f3fa0b96.pdf' -O 'data/amazon_2023.pdf'
!wget 'https://d18rn0p25nwr6d.cloudfront.net/CIK-0001018724/d2fde7ee-05f7-419d-9ce8-186de4c96e25.pdf' -O 'data/amazon_2022.pdf'
!wget 'https://d18rn0p25nwr6d.cloudfront.net/CIK-0001018724/f965e5c3-fded-45d3-bbdb-f750f156dcc9.pdf' -O 'data/amazon_2021.pdf'
!wget 'https://d18rn0p25nwr6d.cloudfront.net/CIK-0001018724/336d8745-ea82-40a5-9acc-1a89df23d0f3.pdf' -O 'data/amazon_2020.pdf'
!wget 'https://d18rn0p25nwr6d.cloudfront.net/CIK-0001018724/4d39f579-19d8-4119-b087-ee618abf82d6.pdf' -O 'data/amazon_2019.pdf'Now let’s set up the system. The API has the same interface as the chat API, and the retrieval process is seamless to the user and only visible through the fields in the response. There are several ways to work with chat APIs. We choose to save the conversation history in a global variable. We also define a default answer in the case where the question should be answered using the documents, but the information is just not there:
# Global variable for maintaining the history
conversation_history = []
DEFAULT_RESPONSE = "I'm sorry, I cannot answer your questions based on the documents I have access to."
def call_convrag(message, labels):
# Convert chat history to convrag messages format
conversation_history.append({"role": "user", "content": message})
url = "https://api.www.www.ai21.com/studio/v1/conversational-rag"
payload = json.dumps({
"messages": conversation_history,
"labels": labels
})
headers = {
'Authorization': f'bearer {YOUR_API_KEY}',
'Content-Type': 'application/json'
}
try:
response = requests.request("POST", url, headers=headers, data=payload)
response.raise_for_status() # Raise an HTTPError if the HTTP request returned an unsuccessful status code
except requests.exceptions.HTTPError as http_err:
print(f"HTTP error occurred: {http_err.response.status_code} - {http_err}")
conversation_history.pop()
return
except Exception as err:
print(f"Other error occurred: {err}")
conversation_history.pop()
return
if response.json()['context_retrieved'] and not response.json()['answer_in_context']:
conversation_history.append({"role": "assistant", "content": DEFAULT_RESPONSE})
else:
conversation_history.append({"role": "assistant", "content": response.json()['choices'][0]['content']})
return response.json()
def print_convrag_response(response):
if response['context_retrieved'] and not response['answer_in_context']:
print(DEFAULT_RESPONSE)
else:
print(response['choices'][0]['content'])Now we want to interact with our assistant. Starting with a simple hello:
message = "Hello, how are you?"
response = call_convrag(message=message, labels=['10k_example'])
print_convrag_response(response)As you can see, we get a generic answer. Obviously, there’s no need to retrieve any of our organizational data to answer this question. Here is the response:
Hello! I'm here and ready to assist you. How can I help you today?Now, let’s ask a question which requires some data. If this was simply a chat model, it would indicate that it doesn’t have enough information to answer the following question:
message = "I want to do some research about Amazon in the last couple of years. Let's start with an easy one - how many employees did Amazon have by the end of 2023?"
response = call_convrag(message=message, labels=['10k_example'])
print_convrag_response(response)Here is the response:
By the end of 2023, Amazon employed approximately 1,525,000 full-time and part-time employees.As you can see, in this case the model went through the retrieval process, and generated an answer based on our organizational data.
Let’s continue the conversation with a more complex question:
message = "Thanks. Any major stock events I should know about, including values and splits?"
response = call_convrag(message=message, labels=['10k_example'])
print_convrag_response(response)Here is the response. Looking good!
On May 27, 2022, Amazon effected a 20-for-1 stock split of its common stock. The shares of common stock retained a par value of $0.01 per share, and accordingly, an amount equal to the par value of the increased shares resulting from the stock split was reclassified from "Additional paid-in capital" to "Common stock".Note that this answer combines knowledge from several different sources in our database.
Feeling emboldened by this success, we may be tempted to ask more questions:
message = "How does it compare to Google's stock?"
response = call_convrag(message=message, labels=['10k_example'])
print_convrag_response(response)When we try that, here is the response we get back:
I'm sorry, I cannot answer your questions based on the documents I have access to.Why does the system answer like this? Because the reports we have in our system only date back until 2019. There is a clear indication by the API that the answer is not in any of the documents, allowing for easy parsing and providing a default ‘No response’ message that you can pre define.
You can see the full conversation history below, as stored in our global variable:
[
{
"role":"user",
"content":"Hello, how are you?"
},
{
"role":"assistant",
"content":" Hello! I'm here and ready to assist you. How can I help you today?"
},
{
"role":"user",
"content":"I want to do some research about Amazon in the last couple of years. Let's start with an easy one - how many employees did Amazon have by the end of 2023?"
},
{
"role":"assistant",
"content":" By the end of 2023, Amazon employed approximately 1,525,000 full-time and part-time employees."
},
{
"role":"user",
"content":"Thanks. Any major stock events I should know about, including values and splits?"
},
{
"role":"assistant",
"content":" On May 27, 2022, Amazon effected a 20-for-1 stock split of its common stock. The shares of common stock retained a par value of $0.01 per share, and accordingly, an amount equal to the par value of the increased shares resulting from the stock split was reclassified from \"Additional paid-in capital\" to \"Common stock\"."
},
{
"role":"user",
"content":"How does it compare to Google's stock?"
},
{
"role":"assistant",
"content":"I'm sorry, I cannot answer your questions based on the documents I have access to."
}
]Looking ahead
Conversational RAG’s planning component, which enables it to efficiently retrieve high-quality output, is just one example of what planning can accomplish in the world of AI systems.
As part of our mission to build market-leading models and GenAI technologies that are purpose-built for the enterprise, we are excited to continue exploring how planning can improve the accuracy, efficiency, and overall reliability of GenAI output.


