
Introducing J1-Grande!
During the past few weeks, we’ve been quietly test-driving Grande with AI21 Studio users. The feedback was incredible. In fact, while Grande is significantly closer in size to J1-Large (7.5B parameters), a great majority of users have found that J1-Grande’s quality is comparable to that of J1-Jumbo (178B parameters). This is great news for all budget-conscious practitioners; J1-Grande, our mid-size model, offers access to supreme quality text generation at a more affordable rate.
Check it out: we asked each of the Jurassic-1 models to generate a humorous poem about a friendship between a dog and a cat:

You’ll find that while each of the three models composed comical (though quite meaningful) poems, Grande and Jumbo exhibit a far more sophisticated level of writing. Try it out for yourself in the AI21 Studio playground.
With a response time twice as fast as Jumbo, at one-third the cost of Jumbo, Grande delivers an excellent combination of price, quality and speed to even the most seemingly complex use-cases. To learn more about subscription plans, visit the pricing page.
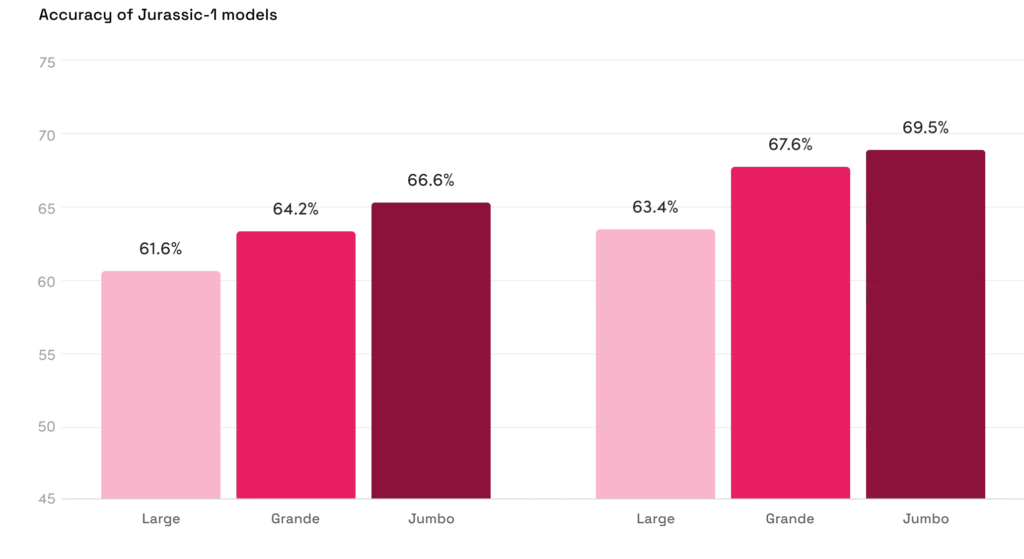
Benchmarks
Distilling the quality of a language model into a single metric is notoriously difficult. Nevertheless, we find it helpful to compare the performance of different models on standard NLP tasks. Below we examine the accuracy of J1-Large, J1-Grande and J1-Jumbo on a diverse selection of tasks, including common knowledge question answering, reading comprehension and common sense.
None of the models were trained specifically for the tasks presented. We compared the models in two distinct circumstances:
- Few-shot: demonstrating with a few examples of ideal outputs for it to mimic (as seen here)
- Zero-shot: void of any guidance whatsoever (as seen here).

Learn more at https://www.ai21.com/studio or try it yourself in the playground.


