Table of Contents

AI21’s Jamba 1.6: The Best Open Model for Private Enterprise Deployment
Today, we’re introducing Jamba 1.6, the best open model family on the market for enterprise deployment, offering:
- Leading open model quality: Jamba Large 1.6 outperforms Mistral Large 2, Llama 3.3 70B, and Command R+ on quality, and Jamba Mini 1.6 outperforms Ministral 8B, Llama 3.1 8B, and Command R7B.
- Unparalleled long context performance: With a context window of 256K and hybrid SSM-Transformer architecture, Jamba 1.6 excels at RAG and long context grounded question answering tasks.
- Flexible deployment: In addition to AI21 Studio, the models are available to download from Hugging Face and deploy privately on-prem or in-VPC, with more deployment options coming soon.
Jamba outperforms Mistral, Meta, and Cohere, and rivals leading closed models in quality, while allowing enterprises to deploy it entirely on-premise or in a VPC—ensuring that sensitive data stays within the organization, never exposed to a model vendor. With Jamba 1.6, enterprises no longer have to choose between the rigorous data security of open models and the leading quality of closed models.
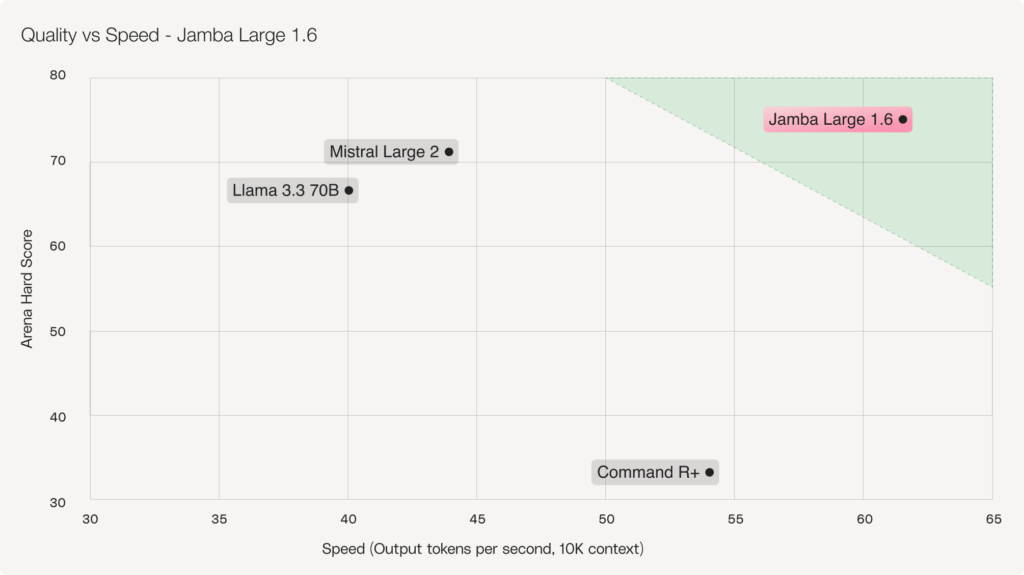
LongBench and ArenaHard scores are from official leaderboards for applicable models. Examples that couldn’t fit models’ context windows were scored accordingly. Due to a 32K context limit in its vLLM deployment, Mistral Large was evaluated through its official API.
Enabling Enterprise Deployment with Private AI
In recent weeks, we’ve witnessed a string of impressive open model releases that have seriously challenged the notion that closed models corner the market on model quality.
Industry analysts are taking note, too. In research released just last month, researchers at CB Insights documented how open models are rapidly closing in on closed model quality.
This pattern opens up new potential for enterprise AI adoption, which has previously been blocked by concerns over data security and privacy when working with closed models, especially among industries handling personally identifiable information (PII), proprietary research, or highly regulated data.
Not only does Jamba 1.6 now lead the open model enterprise market in quality, it does so while maintaining superior speed. Just as data privacy and quality shouldn’t be a tradeoff for the enterprise, neither should quality and latency.
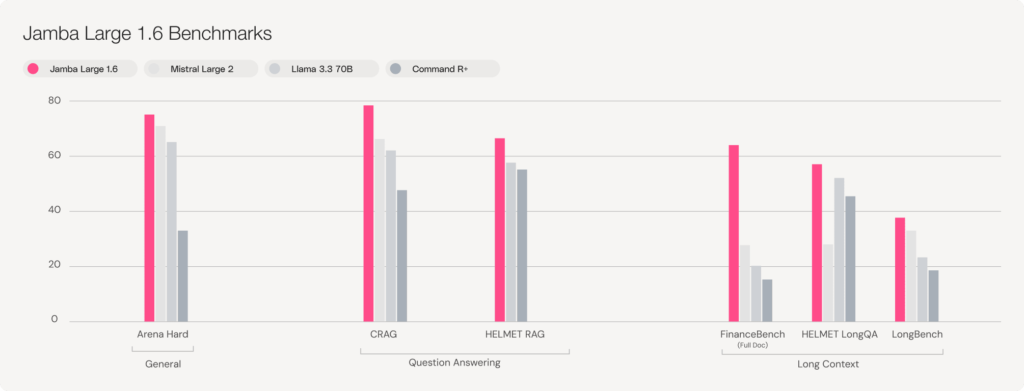
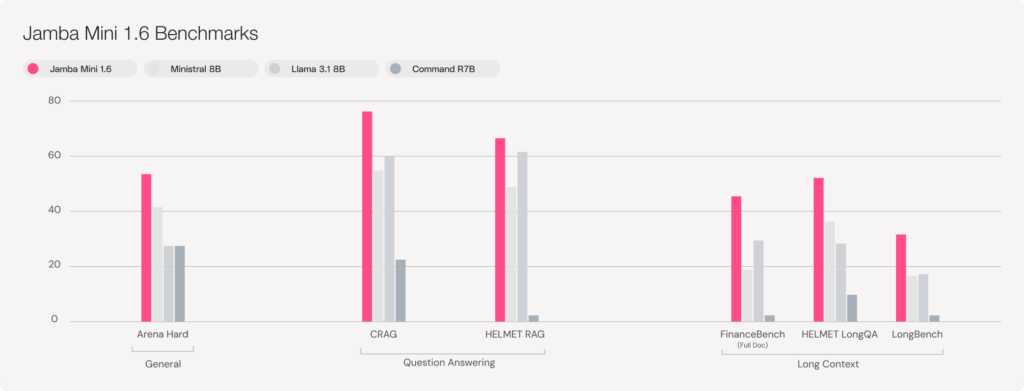
Unparalleled RAG and Long Context Performance
In addition to outstanding overall model quality, Jamba excels at efficiently and accurately handling long context use cases. Built from hybrid SSM-Transformer architecture, and offering a market-leading 256K context window, Jamba outpaces its peers on RAG and long context question answering benchmarks. Whereas other open models collapse as context length increases, Jamba remains accurate—retrieving, synthesizing, and reasoning over massive datasets without performance degradation.
The implications for leveraging long context windows in the enterprise remain clear:
- An R&D team working on new drug discovery needs AI that can retrieve and analyze years of research data without hallucinating.
- A legal team reviewing M&A documents needs AI that can extract key clauses, cite sources, and summarize findings across thousands of pages.
- A financial analyst building risk models needs AI that can reason over hundreds of earnings reports, regulations, and market trends without losing track of the details.
How Our Customers Are Already Using Jamba
Built for the real workflows our enterprise customers care about most—processing vast amounts of data, retrieving and synthesizing long-form documents, and ensuring outputs are grounded, accurate, and effective—Jamba 1.6 is already proving its ability to handle complex enterprise AI workloads with low latency:
- Fnac, a multinational retail chain using Jamba for data classification, saw a 26% improvement in output quality with Jamba 1.6 Mini, allowing them to move from Jamba 1.5 Large to Jamba 1.6 Mini—maintaining high quality while recouping a ~40% improvement in latency.
- In grounded question answering, Jamba 1.6 is powering personalized chatbots for online education provider Educa Edtech with more than 90% retrieval accuracy and citation reliability, ensuring their community of learners get trustworthy answers.
- A digital banking pioneer, advancing an assistant that delivers grounded answers to customer questions, found that Jamba Mini 1.6 scored 21% higher on precision than its predecessor on their own internal tests—and matched the quality of OpenAI’s GPT-4o.
And in text generation, Jamba is transforming e-commerce inventory databases into structured, high-quality product descriptions, reducing manual workload and improving consistency at scale.
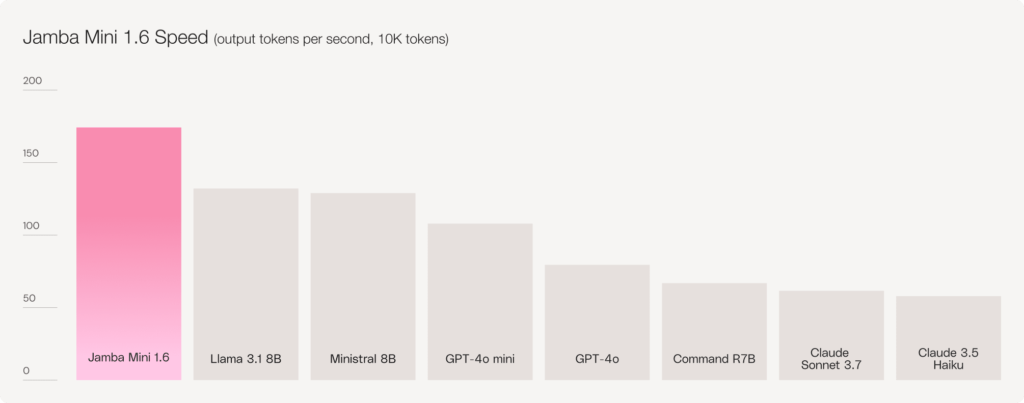
Scale More Enterprise Workflows with Jamba
With this release, we are also rolling out our new Batch API, offering an efficient solution for handling large volumes of requests. Rather than handling requests individually with immediate responses, batch processing enables you to submit multiple requests at once for asynchronous processing.
Whereas most other batch solutions are designed for tasks that are not time-sensitive, AI21’s Batch API is designed for handling high-volume data spikes on a tight turnaround timeline.
For example, in tests with multinational retailer Fnac, we found that using Batch API reduced wait time on tens of thousands of requests from multiple hours to under just one hour, significantly accelerating their ability to review and approve incoming product descriptions. Together with the model’s quality, speed, and data security, enterprises are already demonstrating how Jamba delivers tangible value to their organization.
Start experimenting and building with Jamba today. Chat with Jamba on AI21 Studio or download the model weights directly from Hugging Face. Have a question? Join our community on Discord or start a discussion on Hugging Face.
Looking to securely implement AI workflows in your organization? Let’s talk.


