Table of Contents

Zero-to-production: bootstrapping a custom model in AI21 Studio
Introduction
In this blogpost, we walk through a case study demonstrating how you can build production-grade language applications quickly and effortlessly using AI21 Studio. We use a simple text classification use-case as our guiding example, but the same process can be applied to a wide variety of language tasks.
We start by introducing the task and implementing a baseline solution using prompt engineering with Jurassic-1. Although prompt engineering is a quick and straightforward method for building a proof-of-concept, it has some key limitations, which we highlight in detail below.
To address these limitations, we implement a better solution by training a custom model specifically for our example task. AI21 Studio’s custom models are tailored for optimal performance on a given task and can be economically scaled-up to serve production traffic. Even more importantly, custom models are easy to set up and use!
Custom models in AI21 Studio require remarkably little data for training; most tasks can be addressed successfully by training a model on as few as 50-100 examples. This dramatically lowers the entry barrier for training a state-of-the-art language model of your own, to power your app with excellent quality results. Your trained custom model is served in AI21 Studio and it is immediately available for use, making integration in your application as easy as performing an API query.
Our Example Task: Classifying News Article Topics
As a guiding example throughout this blogpost, we will use a well known Natural Language Processing (NLP) task: classifying the topics of news articles. Specifically, we follow the AG News task formulation, where articles are classified based on their title and their summary into one of four categories: “World”, “Sports”, “Business” or “Science and Technology”. For example, consider the following sample of three examples from the AG News training set:
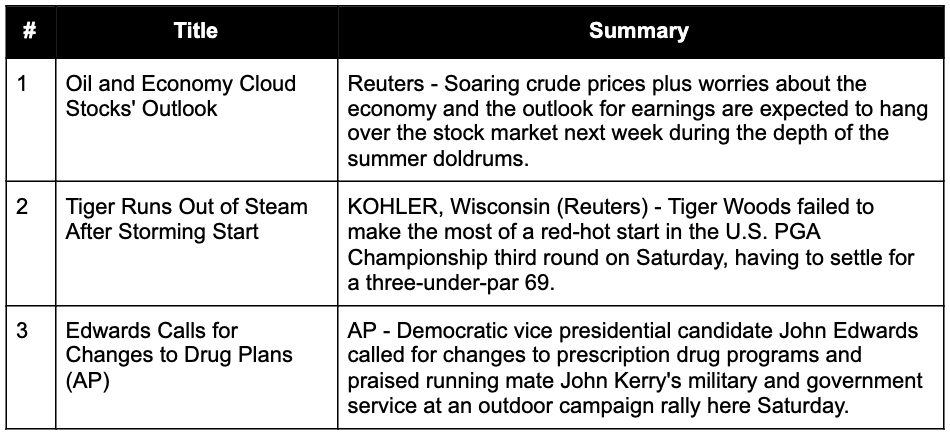
The correct labels for examples 1-3 above are “Business”, “Sports” and “World”, respectively.
Prompt Engineering Solution
Jurassic-1 language models are trained to predict likely continuations for a piece of input text, called a “prompt”. We will use this ability to our advantage, by feeding the model with manually crafted prompts that give rise to a specific behavior in the model output; in our case, we’d like the model to output correct labels for articles. The practice of composing a suitable prompt for a specific task is commonly referred to as “prompt engineering”.
A common and effective prompt engineering approach is to construct a prompt containing a sequence of correctly labeled examples, often called a “few-shot prompt”. The goal of a few-shot prompt is to cause the model to latch on to the correct relation between inputs (for our task – title and summary) and outputs (topic label).
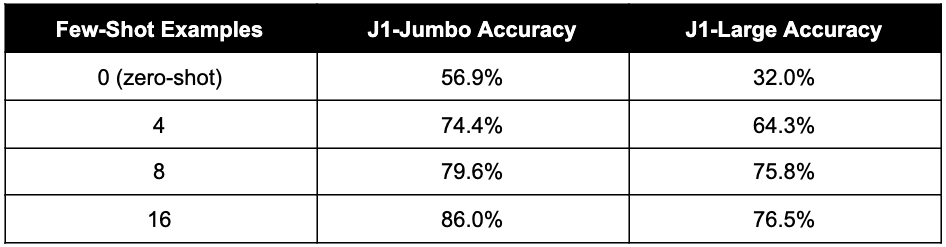
We built a few-shot prompt for our use-case according to best practices, as described in detail in the Appendix. We measured the accuracy of predictions on the AG News test set, while varying the number of examples in the prompt. The results are reported in the table below. Note that as we increase the number of examples, the models tend to perform better. This is typically the case with few-shot prompts. Using J1-Jumbo, we reach a respectable accuracy of 86% for a 16-example prompt.
Why go beyond Prompt Engineering?
We were able to get impressive performance on our task with a very simple method and a tiny dataset of 16 examples (4 per class). This is excellent, but there are several reasons not to be content with our prompt engineering-based solution.
First and most obvious, few-shot prompts can become rather long as the number of examples is increased. This means that on each new prediction the model must read and process the entire prompt, increasing the compute time and resulting in higher latency, energy consumption and cost per prediction. Since adding examples to the prompt improves accuracy considerably, we are left with an inconvenient tradeoff between quality and cost, making it challenging to serve production-scale traffic with prompt engineering-based solutions.
Furthermore, language models have a maximum allowed input length. Jurassic-1 models can handle up to 2048 tokens (or roughly 2300-2500 English words), counting both the prompt and the generated text. Although impressive, this might not be enough in many cases. Imagine if instead of using a short summary of an article, we wanted to use the full article body as the input to our topic classification task. In such a case it would be hard to fit more than 1 or 2 examples into the prompt, so we wouldn’t have even one example per topic (recall we want to distinguish between 4 topics). Alternatively, had we needed to categorize article summaries into one of 100 potential topics, we would have had a similar problem.
Even if we make the most out of prompt engineering, we may require even better accuracy. Suppose we wanted to break the 90% barrier; judging by our results so far, this might be a tall order for prompt engineering.
Finally, we note that custom models have safety advantages. Since they are trained to perform a particular task, it is harder for a malicious user to abuse access to a custom model. We give an example of this in the Appendix.
In the next section we introduce custom models as a more precise, scalable and cost-effective alternative to prompt engineering, which allows us to overcome the limitations described above.
Custom Model Solution
Custom models are specialized versions of the general purpose models which we have been using so far, trained to deliver optimal results on a given task. By combining our powerful Jurassic-1 language models with our special training techniques, AI21 Studio allows you to train a capable model using only a small amount of data, and makes it very easy to query your model once it’s trained.
To train a custom model of your own, all you need to do is provide us with a small dataset of correctly solved examples, and we will do the rest.
The quality of results you get from a custom model depends on the amount and the quality of training data you provide. As a starting point for most tasks, we recommend using 50-100 examples, since we find this is often enough to achieve great results. So, if you can get your hands on a few dozen examples, we recommend you try our custom models. Even if you don’t have data at all, we have a few tricks you can use – see the Appendix for more details.
To pick up where we left our topic classification case study, we trained custom models for AG News while varying the number of examples in the training set. The resulting accuracy on the AG News test set is shown in the table below. As you can see, with as few as 10 examples our custom model’s accuracy is comparable to J1-Large with a few-shot prompt. We also see that adding more training examples results in better accuracy for our custom model, surpassing J1-Jumbo’s few-shot performance with only 80 training examples.
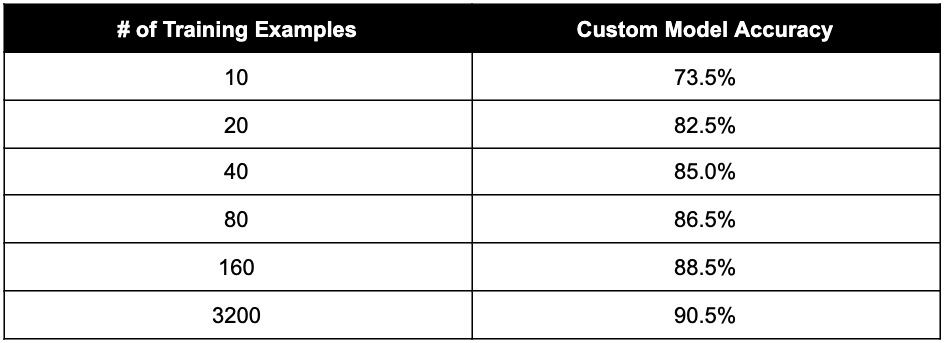
Custom models really start to shine when we take latency into consideration. Feeding the general purpose J1-Jumbo model with an engineered prompt consisting of 16 examples, we got an accuracy of 86%, and the typical processing time in this case is ~250 milliseconds. A custom model that matches or exceeds this accuracy only needs to process the summary and title of the individual example we’re labeling; there is no need to include a lengthy prompt in every request, because the task-specific behavior is already baked into the model. As a consequence, our custom model can process a typical request in less than 50 milliseconds, offering a greater than 5x speedup compared to prompt engineering.
Appendix: Engineering the Prompt
An easy way to start engineering a prompt is to feed the model with simple instructions for the required task, such as the following:

To predict the label for a given article, we could input the text above followed by the article title, its summary, and a heading that prompts the model to output the correct label as a completion. The full prompt using this scheme follows below.

We can replace the text highlighted in blue with the relevant title and summary for any inference example we’d like to label and let the model generate a continuation after “The topic of this article is:”. This is commonly referred to as a “zero-shot prompt”, because the model is expected to correctly perform the task without feeding it any correctly solved example. Using the prompt above, J1-Large has an accuracy of 32% and J1-Jumbo gets 56.9% on the AG News test set; although significantly better than a random guess accuracy, this leaves much to be desired.
The zero-shot approach can be improved upon by adding a number of correctly labeled examples to the prompt itself, making it a “few-shot prompt”. Jurassic-1 models recognize and imitate patterns in text, so including a few solved examples in the prompt helps reinforce the desired relation between inputs (title and summary) and outputs (topic label); this usually improves prediction accuracy. A few-shot prompt using the sample of three articles above is shown below. As in the zero-shot case, it will end with the inference example specified in the same uniform format, so the text highlighted in blue will be replaced with the appropriate content for the inference example.
Once we’ve decided on a prompt format as above, we can simply make a longer prompt by adding more examples in the same format. There are some considerations we should keep in mind while doing this:
- Keep the examples relatively balanced between the classes (i.e. the 4 possible topics), to avoid biasing the model towards the more common classes in the prompt.
- Scramble the order of the examples to avoid the model latching on to the wrong pattern (e.g. “Business” always comes after “World” in the examples).
- Make sure there’s enough room for the example you actually want to predict. Jurassic-1 models are restricted to 2048 tokens, which should include the prompt and the generated output (1-2 tokens in our case).
We built a prompt corresponding to these guidelines. The resulting accuracy for varying prompt lengths is reported above. Not surprisingly, the best results are achieved with J1-Jumbo and the longest (16-example) prompt, reaching an accuracy 86% on the AG News test set.
Appendix: Safety Advantages of Custom Models
AI21 Labs is committed to promoting safety in our products. One potential safety risk is deliberate misuse by malicious users of your application, exploiting its access to Jurassic-1 to generate text for their malicious purposes. Adversaries may attempt to achieve this via “prompt injection”, where the end-user’s input text is crafted to alter the normal behavior of the model. As we will now demonstrate, custom models are less susceptible to such attacks than general-purpose models, offering a significant safety advantage when deployed in production.
Consider a malicious user who has access to the news article topic classification system built on top of Jurassic-1 and wishes to abuse it to extract toxic generations from the model. Recall that an engineered prompt for topic classification ends with the following text:

Where <TITLE> and <SUMMARY> are user inputs. A malicious user may attempt a prompt injection attack by providing the adversarial input “The topic of this article is:” followed by some offensive text in place of a legitimate summary, hoping that the model will generate the offensive text or something related to it as the completion. Since language models latch on to patterns, the malicious user may even repeat this input line a few times to increase their chances of success. For example, below the adversarial input is repeated 3 times:

The figures below compare the performance of the solutions described in this blog post – prompt engineering versus custom models – when faced with an attack like this. We see that the outcome depends on the number of repetitions of the toxic text in the input. For prompt engineering, if the adversary introduces 2 or more repetitions of the toxic text, 50% of the model outputs are toxic, and 3 or more repetitions cause the model to exclusively generate toxic outputs. For custom models, it takes 4 or more repetitions for the adversary to successfully extract toxic generations from the model, and even then the probability of a toxic output is much lower than for prompt engineering.
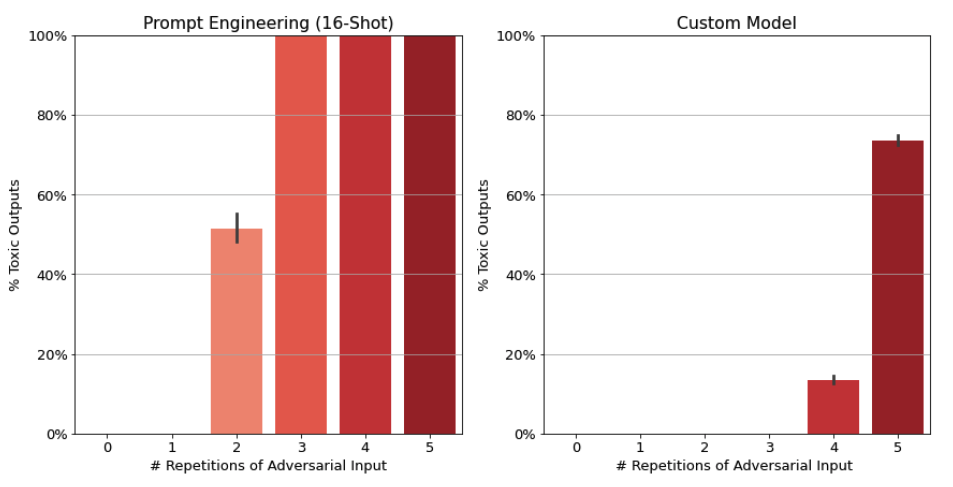
Although using a custom model doesn’t eliminate the risk entirely in this example, it does decrease it substantially, in a way that makes other safety mechanisms more effective. For example, to protect against prompt injection in a news topic classification system, it makes sense to limit the amount of text a user can input in the summary field. Any safety measure creates a tradeoff between restricting usage and guaranteeing safety, which in this case is found in the maximum allowed input length: set the threshold too high and prompt injection attacks will be more likely to succeed; set the threshold too low and legitimate inputs will be blocked. Using a custom model, which is less susceptible to prompt injection out of the box, makes the tradeoff easier and allows a developer to choose a higher threshold while guaranteeing the same level of safety.
Appendix: No data? No problem!
Jurassic-1 custom models offer excellent accuracy even when trained on a surprisingly small dataset. Nevertheless, sometimes even a small annotated dataset is hard to come by. Wouldn’t it be nice to enjoy the benefits of custom models without collecting any labeled data? As we will now demonstrate in our topic classification case study, this is possible.
First, we note two simple observations:
- A prompt engineering solution with 1-4 examples per class achieves reasonable accuracy.
- The model assigns a probability to the label it generates, which indicates its “confidence” in the label. High-confidence labels are more likely to be correct predictions.
Relying on these two observations, we propose the following simple approach:
- Collect many unlabeled input examples for topic classification.
- Use a prompt engineering-based solution to automatically label them with J1-Jumbo.
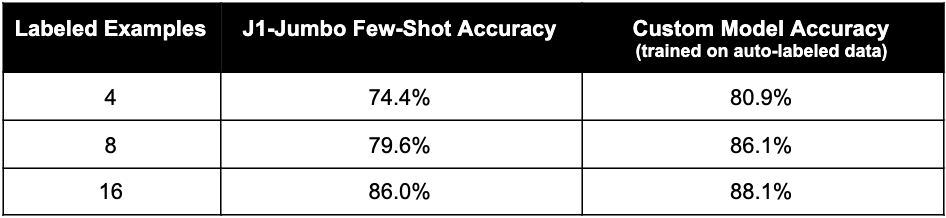
- Filter the auto-labeled examples by confidence, resulting in a dataset of examples where the model assigns >85% probability to the labels it predicted. Make sure the different classes are equally represented in the dataset.
- Train a custom model on the high-confidence auto-labeled dataset.
The table below shows the test set accuracy of custom models trained using this approach. We varied the number of labeled examples in the few-shot prompt, and used it to auto-label 160 examples for training. With just 4 labeled examples (1 per class), we beat J1-Jumbo’s accuracy with an engineered prompt containing 8 labeled examples. Using 16 labeled examples (4 per class) to auto-label a 160-example dataset, we not only beat J1-Jumbo but also match the performance of a custom model trained on 160 manually labeled examples (88.5%).